| ACM MM 2022 |
| Kuo, Chiawei and Tsai, Yi-Ting and Shuai, Hong-Han and Yeh, Yi-ren and Huang, Ching-Chun |
| Abstract |
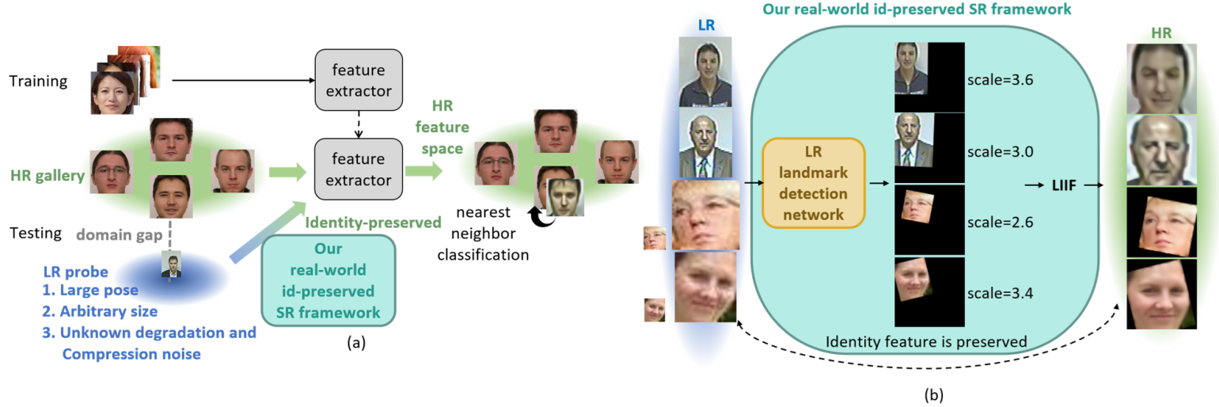 |
| Cross-resolution face recognition (CRFR) in an open-set setting is a practical application for surveillance scenarios where low-resolution (LR) probe faces captured via surveillance cameras require being matched to a watchlist of high-resolution (HR) galleries. Although CRFR is to be of practical use, it sees a performance drop of more than 10% compared to that of high-resolution face recognition protocols. The challenges of CRFR are multifold, including the domain gap induced by the HR and LR images, the pose/texture variations, etc. To this end, this work systematically discusses possible issues and their solutions that affect the accuracy of CRFR. First, we explore the effect of resolution changes and conclude that resolution matching is the key for CRFR. Even simply downscaling the HR faces to match the LR ones brings a performance gain. Next, to further boost the accuracy of matching cross-resolution faces, we found that a well-designed super-resolution network, which can (a) represent the images continuously, is (b) suitable for real-world degradation kernel, (c) adaptive to different input resolutions, and (d) guided by an identity-preserved loss, is necessary to upsample the LR faces with discriminative enhancement. Here, the proposed identity-preserved loss plays the role of reconciling the objective discrepancy of super-resolution between human perception and machine recognition. Finally, we emphasize that removing the pose variations is an essential step before matching faces for recognition in the super-resolved feature space. Our method is evaluated on benchmark datasets, including SCface, cross-resolution LFW, and QMUL-Tinyface. The results show that the proposed method outperforms the SOTA methods by a clear margin and narrows the performance gap compared to the high-resolution face recognition protocol. |