Abstract
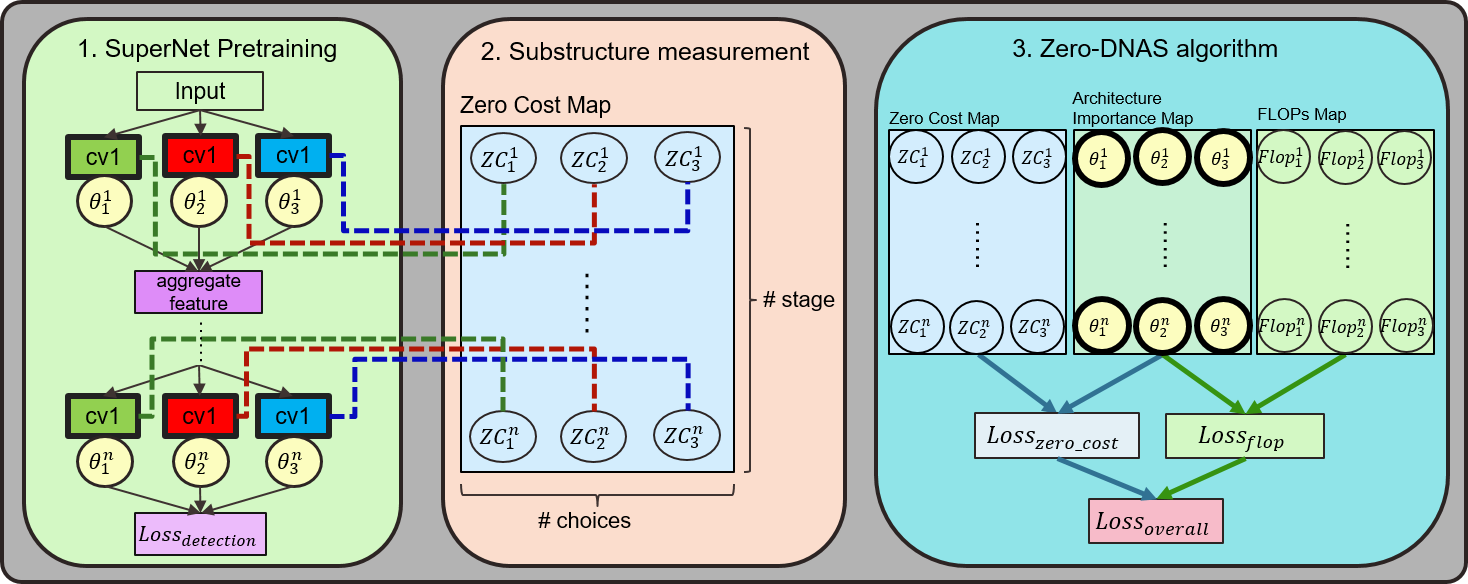
Neural Architecture Search (NAS), which aims to find the optimal network structure undergiven hardware constraints, is typically a complex and time-consuming challenge. Recent re-search has been focused on the Zero-Cost Proxy method, which can rank architectures without requiring training. However, most of these methods have demonstrated applicability primarily in small models and simpler tasks, such as classification. When applied to more complex tasks, they tend to produce unstable results in our experiments. Additionally, traditional differentiable-based and sampling-based NAS algorithms face difficulties when searching for large models due to GPU memory constraints and long training process. In this paper, we introduce IZero-DNAS, a novel approach. It involves pretraining the supernet for a few epochs and then combining the Zero-Cost Proxy with a differentiable-based method to search for the optimal network structure for object detection. Furthermore, we conduct an analysis of the temperature settings in the Gumbel-Softmax used during the pretraining process of the supernet. Our experiments demon-strate that a lower temperature can reduce the interdependencies between candidate blocks in the supernet, thereby resulting in higher scores for zero-cost metrics. The results indicate that our proposed IZeroDNAS is capable of searching for superior network structures compared to manually designed counterparts such as ScaledYOLOv4 and other NAS approaches for object detection.
Experimental Results
1. Poscal VOC2007 Dataset
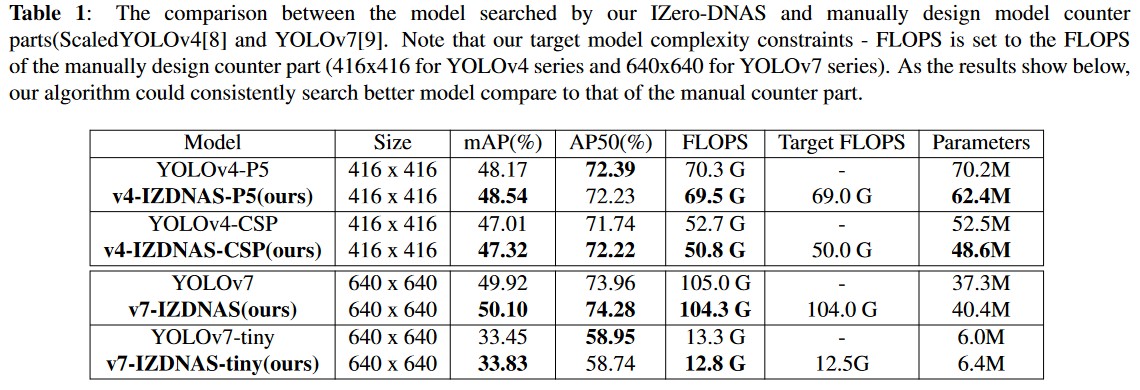
We compare our IZeroDNAS searched model with manually designed models, including the ScaledYOLOv4 series (YOLOv4-P5, YOLOv4-CSP) and YOLOv7 series (YOLOv7x, YOLOv7). In Table 1, bold entries represent models found by IZeroDNAS, outperforming manual counterparts in both mAP and FLOPS. Note that Wang et al. [16] suggest that scaling up and down in network design should consider the longest and shortest gradient paths. However, they don’t provide a concrete relationship between model size and the length of the longest gradient path. In our searched model we figured out that the searched model could further reduce the longest gradient path and lead to better results.
2. COCO Dataset
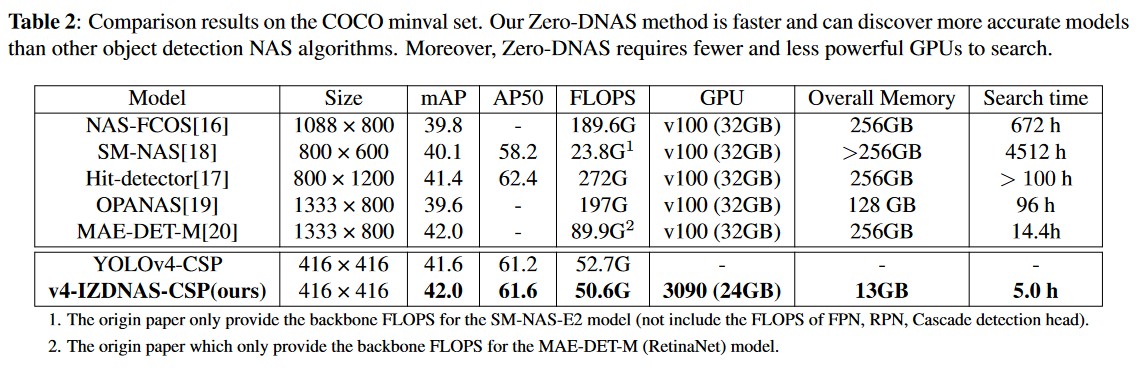
We also compare our searched model with other NAS-Object Detection models on the COCO dataset. Here, we directly apply our searched model and train it in the COCO dataset to show the model generalization. In Table 2, we find the manually designed model outperforms most NAS-based Object Detection algorithms. In contrast, our algorithm takes only 5 hours to search the v4-IZDNAS-CSP model, which is three times faster than the SOTA zero-cost NAS Object Detection model, with superior mAP. Although MAE-DET [22] also yields promising search outcomes, its process demands high-end GPUs to compute the entropy across tens of thousands of models, resulting in a more prolonged search time.
Result Analysis
1. Searched Architecture Analysis
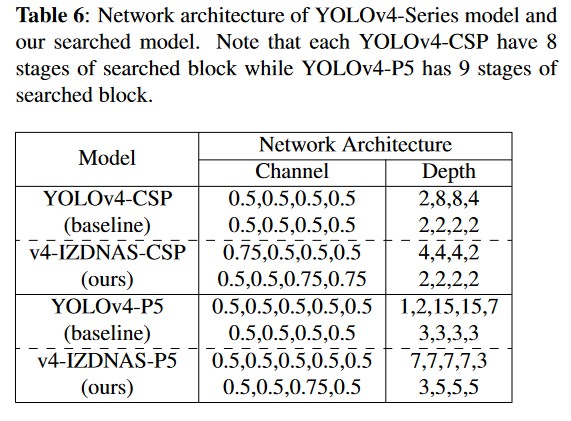
In this section, we delve into the insights gleaned from the searched network architecture. Unlike previous Scaled-YOLOv4 models, which employed a linear increase in net- work depth and channel count, IZDNAS tends to discover models with shallower but wider architectures, challenging the efficacy of linear scaling. As shown in Table 6, YOLOv4-CSP has a depth of 30, while v4-IZDNAS-CSP has a depth of 22. Similarly, YOLOv4-P5 has a significantly greater depth (52 depth) compared to v4-IZDNAS-P5 (49 depth), which further underscores the limitations of linear scaling.
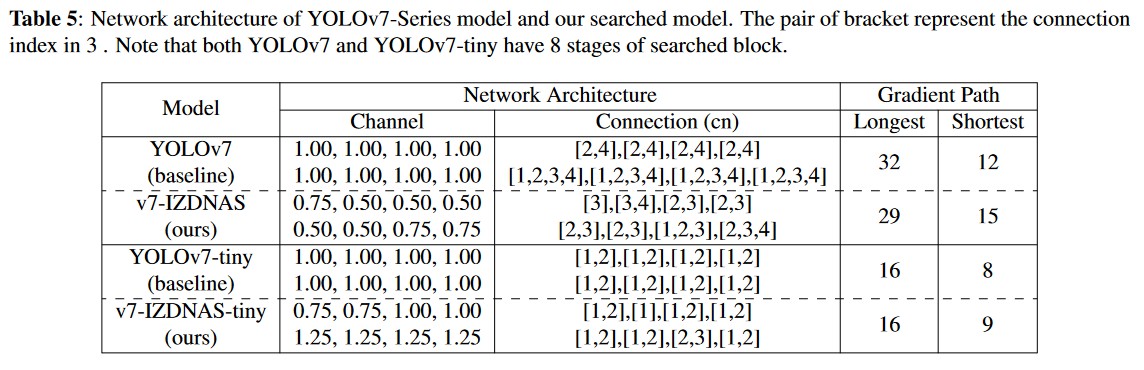
We also present the results for YOLOv7 [9] results in Table 5. Notably, we observe that the v7-IZDNAS model reduces the depth (the longest gradient path), which aligns with the conclusions drawn from YOLOv4’s search version. In contrast, v7-IZDNAS-tiny maintains the same depth. We believe that the tiny version is already underfitting, and therefore there’s no need to further decrease the network depth. On the other hand, most of the searched networks increase the length of the shortest gradient path within the connection structure. While Wang et al.[26] have emphasized the importance of tuning both the shortest and longest gradient paths through various experiments, they did not provide precise guidelines for adjusting gradient paths across models of varying scales. Our algorithm verifies that the existing tuning strategy can lead to suboptimal solutions, whereas our approach can help improve gradient path selection.
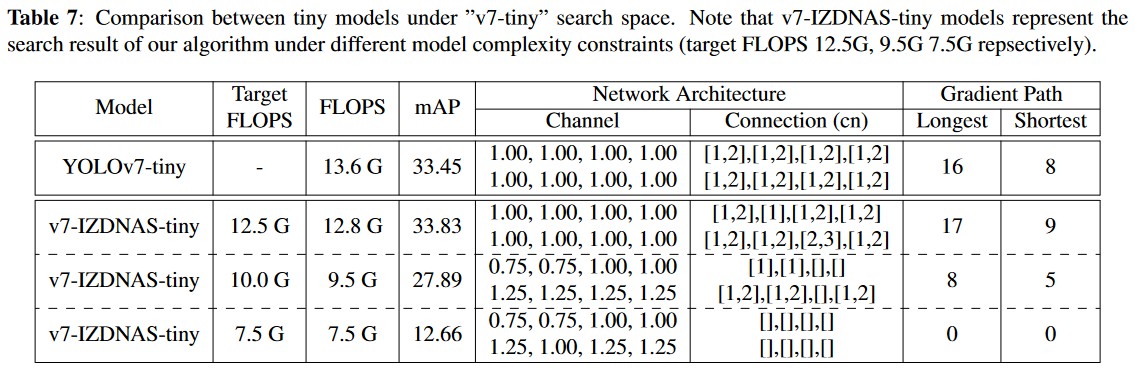
2. Limitation of Smallest Model
In this section, we also analyze the algorithm’s effectiveness by gradually decreasing the model complexity constraint. As table 7 shows, we compare the first two entries of the v7- IZDNAS-tiny (with target FLOPS 12.5G and 10.0G). By reducing 27% of the FLOPS (from 13.0 to 9.5) and discarding most of the connection in the first 4 stages, we observe a 17.5% drop in mAP (from 33.83 to 27.89). However, when comparing the last two entries of the v7-IZDNAS-tiny (with target FLOPS 10.0G and 7.5G) which eliminate the most connection in the last 4 stages, a 21.0% reduction in FLOPS (from 9.5 to 7.5) results in a significant 54.6% mAP drop (from 27.89 to 12.66). This indicates that the last 4 stages contribute more significantly to the accuracy of small models than the back- bone, providing valuable insights into the search direction for low-scale models.